使用 Python 编写 MapReduce -- Hadoop Streaming
要使用其他语言编写 MR 任务,首先要了解一下 Hadoop Streaming
hadoop streaming 简介
Hadoop streaming 是 Hadoop的一个工具, 它帮助用户创建和运行一类特殊的 map/reduce 作业, 这些特殊的map/reduce 作业是由一些可执行文件或脚本文件充当 mapper 或者 reducer。
也就是 hadoop streaming 可以帮助我们使用其他语言(非 java) 来编写 mapper 和 reducer。
下面使用 python 来编写 MR 脚本
工作原理
在 hadoop streaming 中,mapper 和 reducer 都是可执行文件,它们从标准输入流读取数据,使用标准输出流输出数据。
在 python 中就是:sys.stdin 和 print
mapper 和 reducer 会一行一行的读取数据,根据分隔符(默认为 tab)将读入的数据切分为 key 和 value,同时,输出的数据也需要是一个 key,value 对,在第一个 tab 分隔符前的会被认为是 key,后面的都作为 value。
如,输出时 print("%s\t%s", %(key, value))
MR 编写示例
假设有数据如下,下面编写 MR 实现 “倒排”。
1 'bread' 'milk' 'vegetable' 'fruit' 'eggs'
2 'noodle' 'beef' 'pork' 'water' 'socks' 'gloves' 'shoes' 'rice'
3 'socks' 'gloves'
4 'bread' 'milk' 'shoes' 'socks' 'eggs'
5 'socks' 'shoes' 'sweater' 'cap' 'milk' 'vegetable' 'gloves'
6 'eggs' 'bread' 'milk' 'fish' 'crab' 'shrimp' 'rice' 所谓 “倒排” 就是将数据中的每一个字符 word 与其前面的编号 num 对应起来,如 bread,它在编号 1、4、6 中都有出现,因此 倒排 的结果就是:bread 1 4 6。
首先,编写一个 mapper 来将数据拆分为一个个的 word, num 对:
#!/usr/bin/env python
# coding=utf-8
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
num = words[0]
for i in range(1, len(words)):
word = words[i]
print('%s\t%s' % (word, num))
接着,编写 reducer,将同一个 word 的所属编号收集到一起:
#!/usr/bin/python
#coding:utf-8
import sys
output = {}
curWord = ''
wordCount = 0
for line in sys.stdin:
line = line.strip()
word,tid = line.split()
if output.get(word) is None:
output[word] = []
output[word].append(tid)
if curWord == '':
curWord = word
if curWord == word:
wordCount += 1
else:
if wordCount >= 3: # 若一个单词对应的编号数量不少于 3,则输出
print('%s\t%r' % (curWord, output[curWord]))
wordCount = 1
curWord = word执行 MR 脚本
通常执行 MR 脚本需要在 hadoop 系统上工作,但是为了防止出错, mapper 脚本可以在本地测试,而 reducer 脚本通常涉及排序,在本地测试可能会得到错误结果。
本地测试
在当前路径下有 t1.txt 存放数据,mapper/mapper1.py 为 mapper 脚本,在 shell 上运行命令:
cat t1.txt | python mapper/mapper1.py ,这样 mapper 运行的结果就会打印在屏幕上了,若想要输出到文件中,可以使用 > ,即 cat t1.txt | python mapper/mapper1.py > out1.txt
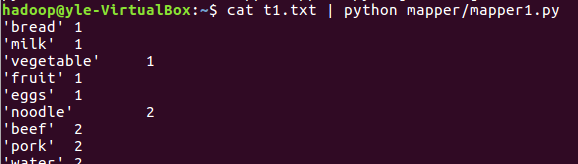
若想要读取一个文件夹下的所有文件的话,则改为:cat data/*.txt | python mapper/mapper1.py
分布式系统上执行
首先,将数据上传到 HDFS 的 /pj 目录下:hadoop fs -put t1.txt /pj
然后使用 hadoop streaming 执行 MapReduce,hadoop streaming 需要提供一些设置参数,可以在命令行中直接输入,也可以编写 shell 脚本来执行(推荐)
来看 shell 脚本的编写,文件命名后缀是 .sh
#!/bin/bash
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.7.jar \
-jobconf mapreduce.reduce.shuffle.memory.limit.percent=0.1 \
-jobconf mapreduce.reduce.shuffle.input.buffer.percent=0.3 \
-jobconf mapreduce.map.memory.mb=512 \
-jobconf mapreduce.reduce.memory.mb=512 \
-jobconf mapred.map.capacity=100 \
-jobconf mapred.reduce.capacity=100 \
-jobconf mapred.job.name=reverse_sort \
-file mapper/mapper1.py -mapper mapper/mapper1.py \
-file reducer/reducer1.py -reducer reducer/reducer1.py \
-input /pj/t1.txt -output /pj/output/ 简单说明一下这个 shell 脚本:
第一行 #!/bin/bash 说明这个是一个 shell 脚本
第二行中的 hadoop-streaming-2.7.7.jar jar 包路径是在自己安装 hadoop 的路径下,应该都会有的
再下面,-jobconfig 的那些参数根据自己的需要来设置,具体可以参照官网 和这篇博客的介绍
而 file、mapper、reducer、input 和 output 是必须的。
其中 file 选项是让f ramework 把可执行文件作为作业的一部分,一起打包提交。
接下来,运行这个 shell 脚本,假设这个 shell 脚本的文件名是 run.sh。
shell 脚本有三种运行方式:
-
先输入
chmod +x run.sh赋予可执行权限,然后在命令行中输入./run.sh即可运行
-
使用
sh run.sh运行 -
使用
source run.sh运行
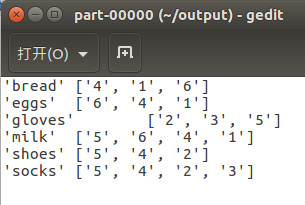
脚本若正确执行完毕,拉取 HDFS 上的结果:hadoop fs -get /pj/output
顺便一提,若不是使用编写 shell 脚本的方式运行,则上面的 hadoop streaming 运行方式为:

即将脚本里的内容全写在命令行中。
关于 hadoop streaming 配置的一些参考学习文章
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
